Last week I let an AI agent help me move LLM Scout from Cloudflare Pages to a hardened VPS origin behind Cloudflare Tunnel.
That sounds more reckless than it was. The difference was the control model.
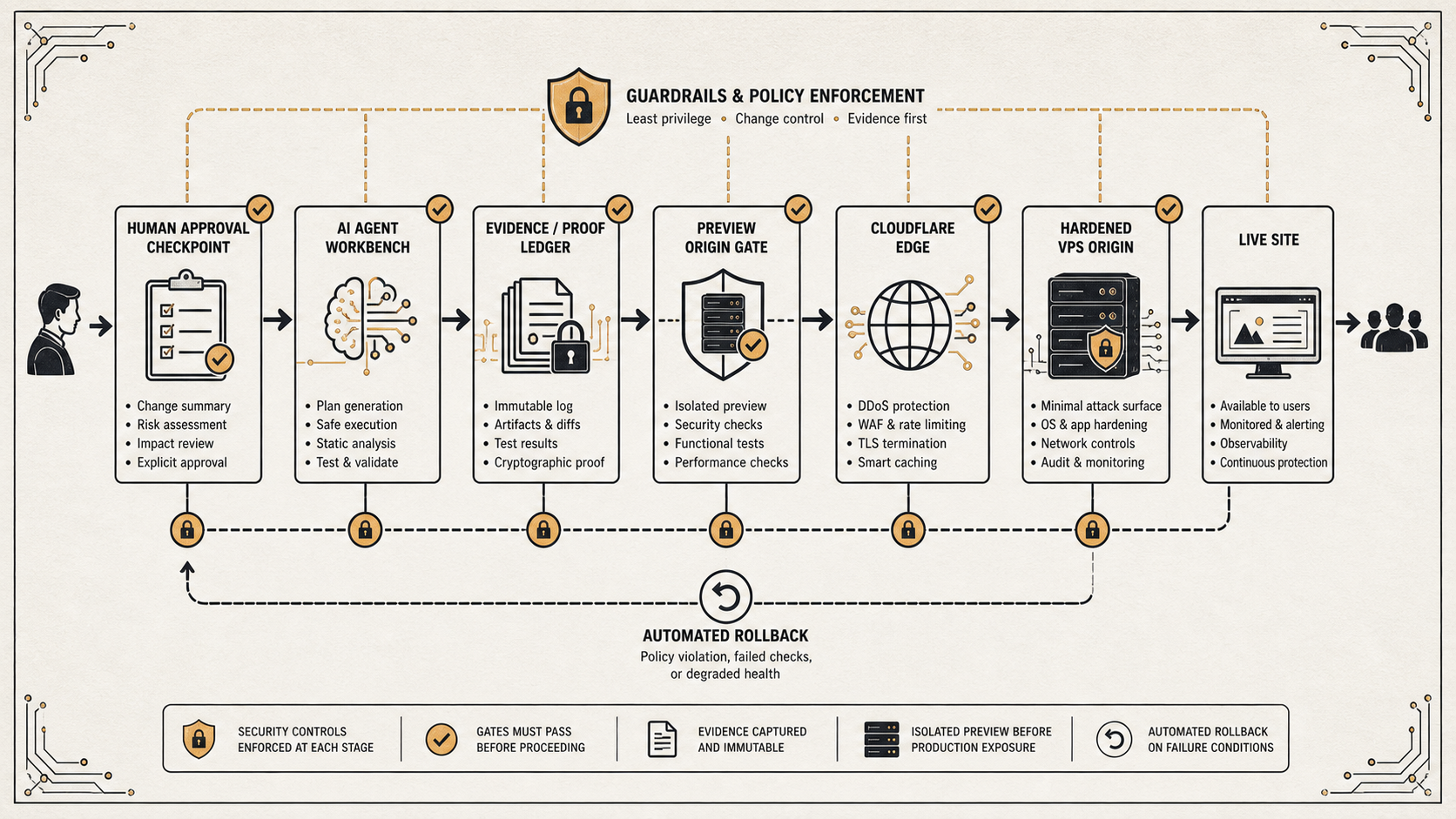
The agent did not get blanket autonomy. It did not silently mutate production. It worked inside a runbook with read-only proof first, explicit approval before production changes, rollback notes written before the switch, and browser-visible checks after propagation.
That is the part of AI agents I think security teams should pay attention to. Not the idea that the model is "smart enough" to run production. The useful part is that a well-scoped agent can keep a lot of operational state in view while the human keeps ownership of the risk decision.
Why this was not just a DNS change
LLM Scout is not only a static homepage. The public site has dynamic model surfaces that have to keep telling the truth after the origin changes:
- homepage Trending on scout
- homepage New Models
- leaderboard APIs
- search and recommendation APIs
- Scout Score V3 behavior exposed through public DTOs
The risk was not simply "does the page return 200." A site can load and still be wrong. It can look alive while serving stale data. It can pass a shallow homepage check while the widgets people actually use are empty, filtered incorrectly, or backed by the wrong API contract.
The real cutover problem was a contract problem:
catalog artifact
-> canonical model identity
-> Scout Score V3 state
-> hardware fit and ranking policy
-> public DTO scrubber
-> API response
-> homepage/search/leaderboard renderIf any link in that chain drifted, the site could be "up" and still misleading. A leaderboard could expose the wrong score state. A search result could carry private scoring fields. A homepage widget could silently filter out new models because it depended on a property the API no longer returned.
That last class of bug is exactly why I cared about browser proof. The tab=trending endpoint being healthy did not prove the homepage Trending on scout region was healthy. The tab=newest endpoint returning rows did not prove the New Models widget would render them. The UI had its own contract.
The control model
The operating model was intentionally constrained. The agent could gather evidence, prepare patches, run tests, inspect diffs, and update runbooks. It could not treat one approval as permission for every later mutation.
- Keep lab and production work separated until the import path was clear.
- Prove the hardened origin on a preview hostname before moving live traffic.
- Run read-only checks before mutation.
- Use service health, API probes, and browser-visible checks, not backend confidence alone.
- Write rollback notes before the switch.
- Require explicit human approval before production-risk Cloudflare changes.
- Import the work back into the production repo by pull request, instead of leaving a mystery server patch behind.
The important detail is that the gates were scoped. Preview repair approval was not live apex approval. Apex approval was not automatically www approval. A passing API probe was not a browser check. A browser check was not a deploy approval. Each boundary had to be named in the context where it mattered.
That is not process theater. It is how you keep an agent from converting vague momentum into production authority.
The model looked like this:
| Gate | What it proved | What it did not prove |
|---|---|---|
| Local validation | Contract tests, unit tests, and scoring behavior still passed in the repo context. | That the deployed origin had the same files. |
| Preview origin | The hardened origin could serve real traffic through the tunnel before live DNS moved. | That apex or www had been safely migrated. |
| API probes | Stats, search, leaderboard, newest, and redirect paths returned usable responses. | That homepage widgets rendered those responses correctly. |
| Browser-visible QA | The product surface users see was populated after propagation. | That future pushes could not reactivate the old hosting path. |
| Production repo import | The server state was reconciled back into reviewable source history. | That the PR was small or pretty. |
A production cutover should leave a paper trail: what changed, what proof was collected, what rollback path existed, and what source history now owns the state. The agent was useful because it could keep that checklist current across a lot of small gates without losing the thread.
What the agent was good at
The agent was good at the operational work that humans often do badly when tired:
- keeping the runbook state current
- comparing local, preview, and live behavior
- turning observed regressions into targeted contract tests
- checking that dynamic widgets still rendered in a real browser
- preserving rollback notes while the plan changed
- carrying the lab work back into the production repository
None of that is magic. It is disciplined execution at high speed.
The most useful pattern was forcing every claim through an observable surface. If the claim was "the deployed file has the fallback guard," the proof was not "the local patch exists." The proof was deployed-file evidence. If the claim was "new models render," the proof was not "the endpoint returns JSON." The proof was the homepage region populated in a browser.
That is where agents can help. Not by replacing judgment, but by making it cheaper to keep asking: what would actually prove this control surface is healthy?
What still required human judgment
The human parts did not go away.
I still had to decide when speed was worth the operational risk. I still had to approve production mutations. I still had to distinguish a blocker from polish. I still had to decide whether the final production import was acceptable as one large pull request, knowing it contained the lab-to-production move, scoring pipeline work, API contracts, origin assets, deployment notes, tests, screenshots, and edge-cache work.
I also had to decide what not to expose in the public story. The useful parts are safe to discuss: domains, general architecture, preview gates, route movement, public DTO behavior, test counts, rollback notes. The unsafe parts are not interesting enough to publish: tokens, account metadata, exact tunnel identifiers, credential paths, and dashboard internals.
That is a healthier model than pretending the agent "shipped production."
The agent helped operate inside the control system. It did not become the control system.
The proof that mattered
The useful proof was layered and deliberately boring.
Local validation covered the code contracts: 102 Node contract tests, 69 Python unittest tests, and 112 pytest tests. The exact counts are less important than the shape of the coverage. The behavior I cared about had been turned into something observable before traffic moved.
Preview proof covered the deployment path. The hardened origin had to answer through the tunnel before the live hostnames changed. Internal files had to stay blocked. Old redirects had to stop leaking localhost implementation details. Search and leaderboard paths had to be fast enough to use, not just technically available.
Live proof covered the user surface. After the apex moved, the homepage had to show both dynamic widgets populated. The trending leaderboard had to return public rows. The newest leaderboard had to return public rows. The www hostname had to follow the same origin path. The old Pages path had to stop being the route users hit.
Then there was a separate deployment-control check: Cloudflare Pages automatic deployment needed to be neutralized so a future GitHub push would not unexpectedly redeploy the old Pages route. That is a good example of a control surface that is adjacent to the cutover but still part of the risk.
That is the practical security lesson: production work is safer when proof is cheap, repeated, and tied to the thing that can actually fail.
Lessons
Autonomy without boundaries is not the product. The useful thing was not an agent with permission to do anything. The useful thing was an agent that could move quickly inside a bounded workflow and stop at approval gates.
Read-only proof should be cheap and frequent. Before changing live state, prove what you can without mutation. That includes route behavior, service health, API contracts, source diffs, and visible UI.
Dynamic surfaces need explicit tests. A homepage widget is a contract. A public DTO is a contract. A redirect target is a contract. If the contract matters during cutover, it should have a test or a named manual proof step.
Browser-visible QA catches what service checks miss. HTTP 200 is not the same as a working product. A populated API response is not the same as a populated UI. Dynamic surfaces need to be seen, not inferred.
Rollback has to be written before adrenaline takes over. The rollback path does not need to be elegant, but it needs to be specific enough that you can execute it under pressure.
Server state must return to source control. Emergency work that only exists on a host is operational debt. The final PR was large because it reconciled the lab-to-production import, tests, deployment notes, screenshots, and current production behavior back into the repo.
Agents are best when they compress toil without removing accountability. The agent can maintain state, write tests, compare behavior, and update runbooks. It should not silently decide the acceptable blast radius.
Where this leaves me
I do not want agents that silently mutate production.
I want agents that can show their work, keep state across a messy runbook, stop at the right approval points, and leave enough evidence that I can trust the next step.
That is less dramatic than the usual AI story. It is also much closer to the work serious teams actually need.
The future of AI-assisted operations should not be "the agent did everything." It should be: the system made intent visible, made evidence cheap, preserved approval boundaries, and helped humans move faster without pretending risk disappeared.
That is a useful direction. It is also a testable one.